python pandas笔记
数据读取
可以读取excel,csv等:
df = pd.read_excel("Name.xlsx")
df = pd.read_csv("Name.csv")Dataframe 的创建
使用字典创建
dic = {'name1':[1,2,3],'name2':[4,5,6]}
df = pd.DataFrame(dic)
>>>
name1 name2
0 1 4
1 2 5
2 3 6指定行列和数据来创建
df = pd.DataFrame(columns=["name2","name1"],index=['A','B','C'],
data={'name1':[1,2,3],'name2':[4,5,6]})
>>>
name2 name1
A 4 1
B 5 2
C 6 3数据类型转换
df = df.astype(str)
取得dataframe其中的数据
假设有如下dataframe
df = pd.read_csv('Info.csv')
print(df)
>>>
name Age Sex
0 A 40 "male"
2 B 23 "male"
1 C 61 "female"注意,这里的索引是0,2,1不是0,1,2。这对我们后面讲解iloc和loc有作用
条件获取
print(df[df['Sex']=='male'])
>>>
name Age Sex
0 A 40 "male"
2 B 23 "male"
# 多条件获取用&连接条件,条件记得用括号括起来loc,iloc
loc:pd.loc[name_of_index,name_of_column]:也就是根据行和列的名字来定位
iloc: pd.iloc[rank_of_index,rank_of_column]:也就是更加行和列的次序(第几行第几列)来定位
print(df.loc[1,'name']) #列索引为1的人的名字
>>> Cprint(df.iloc[1,0]) #第一列的人的第0个数据(python从0开始计数)
>>> B切片(只能获取行)
格式:df[start:end:step]
print(df[0:3:2])
>>>
name Age Sex
0 A 40 male
1 C 61 femaledataframe中数据的删除
假设有如下dataframe
df = pd.read_csv('Info.csv')
print(df)
>>>
name Age Sex
0 A 40 "male"
2 B 23 "male"
1 C 61 "female"
## drop函数
### 删除列
```py
df.drop(columns=['Sex'], inplace=True)
print(df)
>>>
name Age
0 A 40
2 B 23
1 C 61删除行
df.drop(index=[1], inplace=True) # 如果没有传入inplace参数的话,df就不会被修改
print(df)
>>>
name Age Sex
0 A 40 male
2 B 23 male由于传入index和column的参数是一个列表,因此可以批量删除
Dataframe的合并
假设有如下dataframe
df = pd.read_csv('Info.csv')
df2 = pd.read_csv('Info2.csv')
print(df)
print(df2)
>>>
name Age Sex
0 A 40 "male"
2 B 23 "male"
1 C 61 "female"
>>>
name Age Sex
0 AA 44 "female"
1 BB 31 "female"concat函数
简单的增加行数(df2就是df后面要增加的行):
print(pd.concat([df2,df],ignore_index=True)) >>> name Age Sex 0 AA 44 female 1 BB 31 female 2 A 40 male 3 B 23 male 4 C 61 female(这里如果不ignore_index的话,索引就会变成0,1,0,2,1)
简单的增加列数(把df2放在df1右边然后拼上):
print(pd.concat([df,df2],axis=1))
>>>
name Age Sex name Age Sex
0 A 40 male AA 44.0 female
1 C 61 female BB 31.0 female
2 B 23 male NaN NaN NaN其中如果发现拼上不能凑成一个长方形,就把空出来的地方补上NaN,就像上面一样
- dataframe可以直接添加列,不需要使用函数
df['Location']=['Asia', 'Asia', 'Asia']
print(df)
>>>
name Age Sex Location
0 A 40 male Asia
2 B 23 male Asia
1 C 61 female Asiamerge函数
- 按照某列的值来合并(比如按照身份证号码整合一群人的信息)
假设有如下dataframe:
print(df)
print(df2)
>>>
name Age Sex
0 A 40 male
2 B 23 male
1 C 61 female
Name Hobby Talent
0 A literature writing
1 B chemistry energetic
2 C sports strong will按照名字合并:
print(pd.merge(df, df2, left_on='name', right_on='Name'))
>>>
name Age Sex Name Hobby Talent
0 A 40 male A literature writing
1 B 23 male B chemistry energetic
2 C 61 female C sports strong will如果需要可以将多出来的Name行删掉
merge详解:
Dataframe缺失值的填充

Dataframe排序
假设有如下dataframe
df = pd.read_csv('Info.csv')
print(df)
>>>
name Age Sex
0 A 40 "male"
2 B 23 "male"
1 C 61 "female"依照年龄排序
df.sort_values(by='Age', ascending=True, inplace=True)
print(df)
>>>
name Age Sex
2 B 23 male
0 A 40 male
1 C 61 female其中,ascending=True是升序,否则是降序
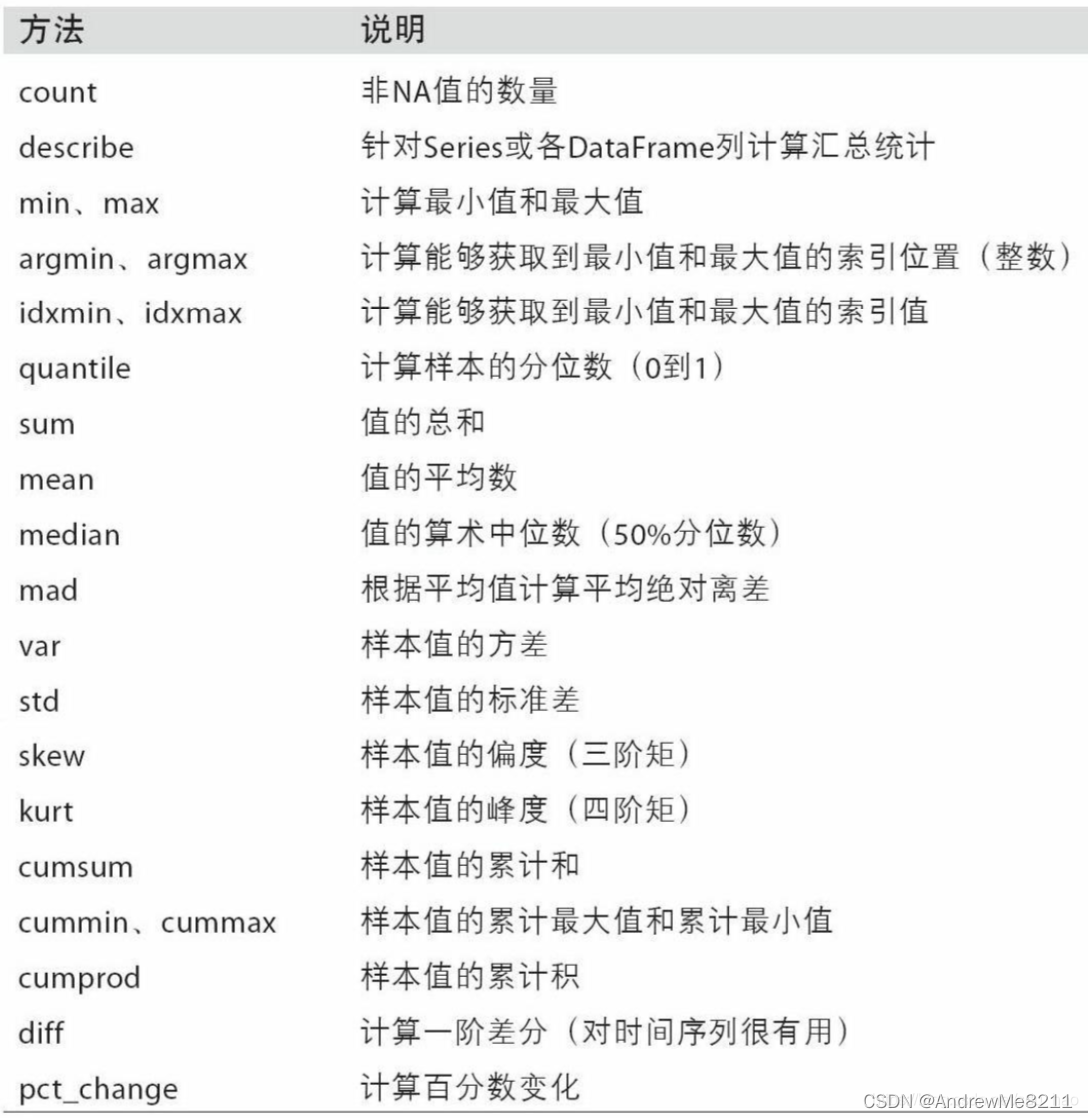
查看dataframe的大致情况
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 AndrewLee!








